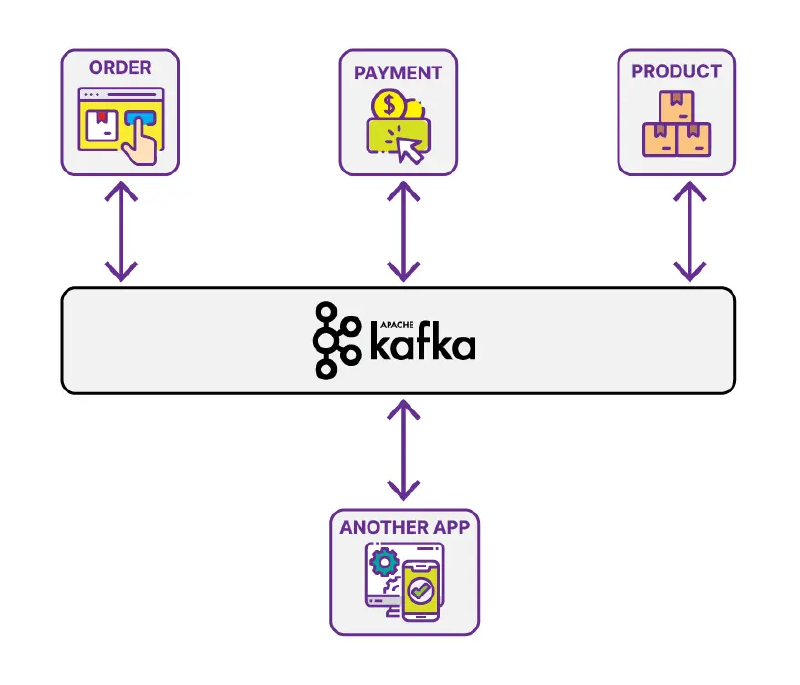
Introduction
Apache Kafka is a distributed streaming platform that is used to build real-time data pipelines and streaming applications. In this tutorial, we will go over the basics of Apache Kafka and how to use it to build a streaming data pipeline. We will also cover how to use Kafka Streams to build a streaming application.
Pub Sub Messaging System
Apache Kafka is a distributed streaming platform that is used to build real-time data pipelines and streaming applications. Kafka is a pub sub messaging system. In a pub sub messaging system, there are publishers and subscribers. Publishers publish messages to a topic. Subscribers subscribe to topics and consume messages from topics. The publishers and subscribers do not need to know about each other. The publishers and subscribers only need to know about the topics. The publishers publish messages to topics and the subscribers consume messages from topics. The publishers and subscribers do not need to be online at the same time. The publishers can publish messages to topics while the subscribers are offline. The subscribers can consume messages from topics while the publishers are offline. The publishers and subscribers can be online at the same time. The publishers can publish messages to topics while the subscribers are consuming messages from topics. The subscribers can consume messages from topics while the publishers are publishing messages to topics.
Kafka Topics
Kafka topics are used to store data. A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber. A topic in Kafka is similar to a queue in RabbitMQ or a topic in ActiveMQ.
Kafka Brokers
Kafka Brokers are servers that store data. A Kafka cluster contains one or more Kafka brokers. A Kafka broker is a server that stores data. A Kafka broker contains one or more topics. A Kafka broker is identified by an ID, host, and port. The host and port identify the Kafka broker. The ID is used to identify the Kafka broker. The ID is used to identify the Kafka broker in the Zookeeper cluster. The ID is also used to identify the Kafka broker in the Kafka cluster. The ID is also used to identify the Kafka broker in the Kafka Streams cluster.
Kafka Producers
Kafka Producers are clients that publish messages to topics. A Kafka producer is a client that publishes messages to topics. A Kafka producer is identified by a client ID, host, and port. The host and port identify the Kafka producer. The client ID is used to identify the Kafka producer. The client ID is used to identify the Kafka producer in the Zookeeper cluster. The client ID is also used to identify the Kafka producer in the Kafka cluster. The client ID is also used to identify the Kafka producer in the Kafka Streams cluster.
Hands-on Demo: Real-time WordCount with Kafka Streams
Kafka Cluster with Docker
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| version: '2'
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- "22181:2181"
kafka:
image: confluentinc/cp-kafka:latest
depends_on:
- zookeeper
ports:
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
|
Run the following command to start the Kafka cluster.
Kafka Producer With Java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* @author flursky
*/
public class FakeTextProducer {
public static void main(String[] args) throws InterruptedException {
Properties kafkaConfig = new Properties();
kafkaConfig.put("bootstrap.servers", "localhost:29092");
kafkaConfig.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
kafkaConfig.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Faker faker = new Faker();
Producer<String, String> producer = new KafkaProducer<>(kafkaConfig);
while (true) {
String text = String.join("\n", faker.lorem().sentences(faker.number().numberBetween(1, 5)));
System.out.println("==================== SENDING TEXT TO TUTORIAL_TEXT ===========================");
System.out.println(text);
System.out.println("==============================================================================");
producer.send(new ProducerRecord<>(WordCountKStreams.IN_TOPIC, text));
Thread.sleep(2000);
}
}
}
|
Kafka Streams WordCount With Java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.*;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.Produced;
import java.util.Arrays;
import java.util.Properties;
/**
* @author flursky
*
*/
public class WordCountKStreams {
public static final String IN_TOPIC = "TUTORIAL_TEXT";
public static final String OUT_TOPIC = "TUTORIAL_WORDCOUNT";
public static void main( String[] args ) {
Properties kafkaConfig = new Properties();
kafkaConfig.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-streams");
kafkaConfig.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29092");
kafkaConfig.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
kafkaConfig.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.Long().getClass().getName());
final StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> source = builder.stream(IN_TOPIC, Consumed.with(Serdes.String(), Serdes.String()));
source.flatMapValues(value -> Arrays.asList(value.split("\\W+")))
.map((key, value) -> new KeyValue<>(value, 1L))
.groupByKey()
.reduce(Long::sum)
.toStream()
.filter((key, value) -> value > 50)
.to(OUT_TOPIC, Produced.with(Serdes.String(), Serdes.Long()));
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, kafkaConfig);
System.out.println(topology.describe());
streams.start();
}
}
|
Kafka Consumer With Java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| import com.majesteye.tutorials.WordCountKStreams;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class WordCountConsumer {
public static void main(String[] args) {
Properties kafkaConfig = new Properties();
kafkaConfig.put("bootstrap.servers", "localhost:29092");
kafkaConfig.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
kafkaConfig.put("value.deserializer", "org.apache.kafka.common.serialization.LongDeserializer");
kafkaConfig.put("group.id", "group-1");
KafkaConsumer<String, Long> consumer = new KafkaConsumer<>(kafkaConfig);
consumer.subscribe(Collections.singletonList(WordCountKStreams.OUT_TOPIC));
while (true) {
for (ConsumerRecord<String, Long> record : consumer.poll(Duration.ofSeconds(3))) {
String key = record.key();
Long value = record.value();
System.out.println(String.format("Word: %s\tCount: %d", key, value));
}
}
}
}
|
Kafka Config Object
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| // Kafka Producer Config
Properties kafkaProducerConfig = new Properties();
kafkaProducerConfig.put("bootstrap.servers", "localhost:29092");
kafkaProducerConfig.put("key.serializer", "org.apache.kafka.common.serialization.LongSerializer");
kafkaProducerConfig.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Kafka Consumer Config
Properties kafkaConsumerConfig = new Properties();
kafkaConsumerConfig.put("bootstrap.servers", "localhost:29092");
kafkaConsumerConfig.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
kafkaConsumerConfig.put("value.deserializer", "org.apache.kafka.common.serialization.LongDeserializer");
kafkaConsumerConfig.put("group.id", "group-1");
// Kafka Streams Config
import org.apache.kafka.streams.StreamsConfig;
Properties kafkaConfig = new Properties();
kafkaConfig.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-streams");
kafkaConfig.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:29092");
kafkaConfig.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName());
kafkaConfig.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.Long().getClass().getName());
|